
The Implications of Your Decisions

Yesterday I came across an article on The Register about the anti-virus software AVG. To quote The Register:
In late February, AVG paired its updated anti-virus engine with a real-time malware scanner that vets search engine results before you click on them. If you search Google, for instance, this LinkScanner automatically visits each address that turns up on Google’s results page.
This has two very large implications, especially when you consider that more than 20 million people have downloaded AVG. And as you can imagine, it has to do with the bandwidth.
Let’s take an example of what happens when you go to Google and search for “latest movies”. In the past you would go to Google’s search page, enter in your search, and get some results. Then when you clicked on one of those search results you would go to that page. Simple, and it’s what you would expect.
However if you have the latest version of AVG installed something else happens. You start the same way, go to Google, enter in your search term (“latest movies”) and click on the Search button. However here is where things change for the worse. AVG looks at the search results and behind the scenes starts to download each and every search result webpage. This is without you having to view or visit the webpage, it’s all happening behind the scenes.
Why is this bad? Because most ISPs (Internet Service Providers) limit how much bandwidth you can use per month. It might be very high for some people, but now imagine that for every search you do, you visit 10 webpages (the default number of search results on most search engines). Even if you don’t look at any of the search results. You’ve basically increased your bandwidth consumption by ten times for every Google search!!! And not just Google, for all search engines, including Yahoo, MSN, etc. Your bandwidth usage has just significantly increased, by multiples.
But it gets worse. What if the webpages AVG decides to check out behind the scenes aren’t just simple pages but rather webpages rich in media that include videos, images, and so on? You’re bandwidth will be consumed in no time. And what if you have more than one computer on your network? What if you have 2-3 computers in your home? If everyone is searching at the same time you can imagine that your network will get slower because everyone is trying to load multiple webpages at the same time. And don’t even get me started on corporate networks. I can’t imagine the increased load on a corporate network with 10-1000 users!!! For that reason alone I suspect corporations will stop using AVG, the bandwidth usage is just too expensive.
And right now this is only officially happening for search engine results, but what if one day they decide to continue down this path and do this for every webpage? I’d hate to see the bandwidth usage on that decision! Most websites have more than 10 links on them! The front page of this blog probably has closer to a 100 links than 10 links on it. So instead of 10 times as much bandwidth, you’re looking at 10-100 times! You’ll be eating up your bandwidth cap each month. And corporate networks will crawl to a halt.
But what about the websites themselves? The websites you visit might also significantly slow down. Let’s take an example using the assumption that AVG visited every link on every page to amplify the issue (even without this assumption, on some search terms the increase in traffic can be very significant). When You go to my company’s website LandlordMax, the landing page (the first page) has at least 20 links. The navigation alone is about 10 links. That means our servers now would have to be able to handle 20 times as much capacity to handle the same number of users (assuming they all used AVG). That is, every person who comes to our website would not just download the first webpage, but instead they would download 20 webpages. And each time they clicked on a link, they would get another 20+ pages. We’d have to increase our server capacity by 20 times. That’s very expensive, and where do you think that cost would have to eventually be offset? Into the price.

But assuming it doesn’t get to this level, right now for every search term we get listed on the first page, we’ll basically get hit with a webpage request. So for example, if the search term “latest movies” get 10,000 searches a month (from people using AVG), and we’re listed anywhere on the first page, we’ll have to handle 10,000 webpage requests even though only a percentage of that search traffic will come to our site as shown in the above graph. Who’s going to pay for all that bandwidth? It’s certainly not AVG! It’s both you the user of AVG and the website owner.
It gets even more interesting, assuming bandwidth is free. In the example above, let’s say it’s now your website and you’re the 10th search result listing, at the very bottom of the first page. In this case you can expect to get about 3% of the traffic, or using our example of 10,000, 300 visitors a month. Now, with the new AVG system, you can expect this number to dramatically increase. Instead of just 3% or 300 visitors a month, you’ll get 100% of the traffic, a full 10,000 visitors a month. That will greatly skew your web metrics and webserver needs. In this example you’ve just increased your traffic (and hence server capacity needs) by almost 3 orders of magnitude! This will affect how you run your website/business. If nothing else, it will increase your costs which means it will have to be offset somehow (usually an increase in price for the customer).
Above this, a lot of the decisions for online businesses are derived from the web metrics. With this new system the metrics of your visitors are now completely useless. The 10,000 visitors a month mean nothing. They don’t represent the true scale of traffic. You’ve basically lost the ability to determine what works and what doesn’t. Although I won’t get into the details here, let’s just say that this means you can no longer correctly determine when and why you have a “real” increase in traffic. It’s all masked in a barrage of fake traffic. And because your web metrics are useless, your marketing now becomes guesses in the dark. Which then means more dollars have to be spent to make the same amount of money. Again this will eventually have to be offset into the price of the products/services on your website.
In any case, this appears to be a very good example of a lose-lose scenario. No one wins. Of course it’s not as drastic as I’m making it out to be, AVG only accounts for at most 20 million users. But it’s very important to realize that this is a significant amount of users. It’s enough that not only have consumers begun to take notice, but many websites are also starting to report significant increases in traffic and bandwidth due to this issue.
What’s really irritating about all this is AVG’s Chief of Research (Thompson) response according to the Register:
And if that causes problems for webmasters, Thompson says, so be it. “I don’t want to sound flip about this, but if you want to make omelets, you have to break some eggs.”
Be careful of the implications of your decision. This may result in a very large community backlash, especially when it’s backed by a large number of webmasters. We all remember the Intel processor fiasco of 1993, commonly referred to as one of the biggest technical blunders of all time.
And on that note I’ll leave you with some after-thoughts to ponder.
- What happens if the search result returns another search result (this could be maliciously implemented)?
- You’re now exposed for exploits from every website on the search results, not just the ones you visit.
- What’s your monhtly bandwidth cap?
- What will be the performance impacts on your machine for continually scanning all those extra webpages for viruses, spyware, and malware?
Permalink to this article Discussions (6)
Top 16 Podcasts

Recently I purchased myself an iTouch, and I have to say it’s an amazing little device. My only complaint so far is that I purchased the 16Gb rather than the 32Gb (I always seem to be running out of room because of all the podcasts I load up on it). Actually, that’s not really true, I’m finding that iTunes on Windows is another of my complaints, it’s an extreme CPU hog. Just downloading files often brings the CPU usage to 100%. Who knows why…
In any case, here’s my current list of the best podcasts I was able to find:
Marketing
Software Development
- IT Conversations
- Software Engineering Radio
- StackOverFlow
- Java Posse
- IBM developerWorks
- UIE Brain Sparks
Technology and Science
General
Some of these podcasts are obviously better than others, but overall I’ve enjoyed almost every podcasts from every single one of these sources. If I had to pick my favorites, they would be Ted Talks (the speakers at Ted are just amazing – I can’t say enough about these video podcasts), Internet Marketing Insider, StackOverFlow, Software Engineering Radio, and Java Posse. I’d also like to include IT Conversations in this list but it’s still too new to me. And don’t get me wrong, the others are great, these just happen to be the best of the best.
And if I’ve missed your podcast, or if you know of other great podcasts, please don’t hesitate to comment below. I’m always on the lookout for great podcasts, especially video based podcasts (video casts).
Permalink to this article Discussions (0)
Why You Should Never Publish Anything Late at Night When You're Tired

I broke one of my own golden rules last night, never ever release or publish anything late at night when you’re tired. If you do the odds of making a mistake greatly increase. And unfortunately last night I broke this rule and a mistake did happen. Luckily for me the mistake was minor, but it helped to reinforce what I should have already known.
You see I published my latest blog entry How Much is it Worth to You? after midnight last night. Although I often stay up much later than midnight, I’ve been going to bed earlier in the last while to catch up on some much needed sleep. In any case, the issue is that I was tired and it was late for me that particular night. Normally in these cases I still go ahead and “publish” the article, but I set the “publish time” to be sometime the next day.
I do this because of several reasons, the biggest reason being that I’ll have had some time to rest and be more awake before it gets publicly released. In some cases I’ve had the time to rethink parts of my post and add more information, sometimes adjust the example, and so on. But overall it’s prevented me a few times from making silly and stupid mistakes.
Well last night I went ahead and pushed the publish button, deciding that I’d break my own golden rule just this one time. And this was my mistake!
Some of you might have noticed it, but I think I caught it before most of you did. What happened is that when I wrote the article I initially left the headline blank. I often do this because I couldn’t think of a good headline at the time I wrote the article. In these cases I just continue writing and come back to the headline later.
Last night I forgot to come back later and write my blog post headline. I left it blank. Above the title being blank, it also meant that my RSS feed subject line was blank. No so bad for a starting blog, but as you get bigger it will be noticed by more and more people. Like I said before, this was not a major issue, but it definitely brought the point of my golden rule home. Plus it’s better to fall and learn (or in this case re-learn) from smaller mistakes than from your larger mistakes.
And don’t think this doesn’t happen to large companies releasing major new versions of their software. To give you an example, early on in my programming career, long before I started LandlordMax, at least 10-15 years ago, I worked for a company where a short workday was 12 hours. And that included weekends (this alone has the makings of a DailyWTF written all over it). As you can imagine we were living in a perpetually tired state. Come release time there was even more pressure to work harder and longer hours. And I did, after all this was very early in my career and I didn’t know any better.
Well the obvious happened. Something eventually went wrong one day. Although I can’t remember the details any more, it’s all a big blur, but I do remember one major release that we’d been working particularly hard to get out the door. We’re talking barely enough time to go home to shower and eat at night (or should I say the wee hours of the morning), never mind sleep. Well eventually we made a mistake, and it was a bigger one. On release night, after what we thought was exhaustive coding and testing, we felt like the current release candidate was ready to go. We decided to release it. We were done. Phew. So we performed one last final build to run one last final test round on (remember this is a time before automated tests were mainstream). And we released it. Exhausted we all went home to catch a few hours of sleep.
Unfortunately within a few hours we were all called right back into the office. Our released version had a major bug. I wish I could remember what it was exactly, but I can’t. To be honest I suspect my brain has intentionally forgotten about it. In any case it was broken and customers were complaining. All hell was breaking loose.
Being already tired really didn’t help to resolve this issue quickly. But lady luck was on our side because it was a very simple mistake and we were able to fix it very quickly (I think it was something like the wrong language properties file was being picked up in the wrong build). So simple a mistake that had we released it in a waken state, well even in a just non-exhausted state, it would never have happened. As soon as we re-released it the phones stopped ringing and we were able to finally get some sleep.
Never ever release when you’re tired. But more importantly, had the issue been a complex or hard one to resolve we would have been in a lot of trouble. Having your development team completely exhausted trying to fix a critical and complex bug during a firestorm is an incredibly dumb place to put yourself into. Would you want to have triple heart by-bass surgery performed on you while you were in the middle of a heart attack by a surgeon who had slept only a few hours in the last week and was living completely on caffeine? Especially when there’s no need for it to be like this.
You can’t win every time, but stack the odds in your favor! Be smart about it. Don’t make my mistake. And you can be sure I won’t break this golden rule again, at least not for a very very long time.
Permalink to this article Discussions (5)
What would it cost to build this site?

Earlier this month there was a thread on Joel Spolsky’s BoS (Business of Software) discussion forum asking What would it cost to build this site. Of course it started innocently enough, with a simple statement:
We recently created a startup on which the website is an integral part. Customers rent our product for a specified time period. When you get right down to it, the required features of the website are no different than what would be required of a car rental web site.
Then came the big question:
My question is, what would a ballpark estimate of the cost be?? Again, the fully functional site would resemble a car rental company such as Hertz.com
This is a completely loaded question!!! There will of course be very large price fluctuations amongst the responses no matter who you ask, these requirements are too broad and open-ended. Sadly however I believe that none of them are near the “real” cost to build this website. I think the highest was around $150k if I remember correctly, with many saying that it could cost as little as a few thousand.
WHAT???
Honestly, to create a car rental service just like Hertz will cost a lot more than $150k. Thinking it will only cost a few thousand is insane. Sure you can say you will outsource it for a few thousand, but I can guarantee you what will come back won’t be what you expect. The price has to be reasonable. If it only cost a few thousand to successfully build this system, than all software, and I mean ALL software, would be outsourced. This isn’t the case. I have no doubt it cost Hertz a lot more.
It’s simple to over simplify how much effort is required to build a software application. So much so that the original poster chimes back in with:
There is just no way this would bet done under $10,000. As I said, the site is about 30 percent of what it needs to do. 5,000 lines of code, couple hundred manhours. The manhours are high as we constantly were changing things. But things are a bit more static now and it would be easier to write a detailed spec for he the remaining requirements.
Some additional “Major” components:
Security/Logins. Certain Admin people will be able to do everything. Lower levels will have limited capabilities.
Audit trails for all changes by personnel. If someone changes a record or changes a reservation it needs to be logged.
RealTime Inventory Management. If inventory is low at certain times then site needs to prevent reservations from taking place. Also ensure inventory was the right stuff when it is returned.
Again, think rental car website. I was thinking more along the lines of $50K to $150K.
Just reading these specs I can very quickly see this site greatly increasing in complexity and scope as the details are filled in. Never mind that the scale of users or data hasn’t even been taken into consideration. In any case, I personally don’t believe that this is possible for $150k, it way too optimistic. The vast majority of the posters are thinking of the simplest solution, but I can already see from this slightly “enhanced” description that it’s not going to be the simplest solution. The requirements are only going to grow, and grow fast they will, otherwise known as scope creep in the software industry.
But alas not everyone agrees. Further down someone comments:
I dunno ’bout 100K. My devs do quite a bit of these sites in the $20K to $50K range … but we don’t have a tight enough spec yet do we? Could (maybe) hit the 6 figures once the full spec is known. The folks suggesting a couple of grand, though, they’re smokin’ crack.
Even though this person agrees that building it for a few thousand is too cheap, he still suggests a price that’s way too low. I have no doubt it cost Hertz much much more. I agree that a simple car rental system could be built for around $100k, but that’s a SIMPLE AND MINIMALISTIC car rental system and NOT a replication of a full blown car system as is suggested. Audit trails, realtime inventory management linked to reservation system, reservation system, scheduling, etc. And these are just listed as “SOME” additional “MAJOR” components. This is not a simplistic system. It will grow in scale very quickly. Just look at some of the questions and issues that came up when we decided to add “simple” email to LandlordMax. And that’s just simple email!
So what’s going to happen. The person will eventually settle on someone who says they can build it for around what they think is reasonable. The delivered system either will not work at all, it will be severely delayed, or it will be severeled scaled back in terms of features and modules. Not only that, but assuming something is delivered, I doubt that it could scale up in terms of traffic load. At least not at that price, scalability takes skill and experience, not to mention effort.
And I haven’t even talked about bug fixing! What do you think happens when a software project can’t possibly be delivered within it’s deadline? Depending on how ethical your company, they might just deliver it in an unstable state where “fixes” will be added to the cost of the project after delivery. For example some software consulting firms are know to do this, deliver a project “on time” only to have the “support” costs be higher than the initial project costs. This way they can be the lowest bidder but yet still charge the real cost of implementing the software. And don’t think it doesn’t happen, it’s much more prevalent than you might think.
Software takes time and effort to build. It’s not that simple yet people continue to grossly underestimate the cost of development and wonder why things it’s late, why it’s buggy, why it just doesn’t work. The answer is simple, extremely simple, many many software projects grossly underestimate the amount of effort required. Although many people want to believe it’s more complex than that, it’s really just as plain and simple as that.
Permalink to this article Discussions (2)
The Scariest Day of a Software Release

What’s the scariest day of a software release? Is it the day before the release? The day of the release? It’s neither, the scariest day of a software release is the day after the release.
Why? That’s when all hell can break loose. That’s when your software will move from your small testing world to the big real world, when it will really be tested beyond the small and friendly confines of your company. That’s when you’ll know if there’s a problem and you’ll be called upon to fix it right NOW. Not tomorrow or next week but right now. The day after the release is by far the scariest day of a software release.
Don’t get me wrong, there’s a lot to bringing a software release to fruition. It takes a great amount of effort. And there’s definitely a lot of pressure to get it right. But all that’s nothing compared to the nightmare of having to deal with a software release gone bad. It can mean rolling back, losing data, angry customers, customers who’s entire companies go down because of you. It’s not a good position to be in.
It’s also when the customer wants solutions and answers right now! How can this have happened? When will it be fixed? And you need to give them an answer and solution NOW. You’re on the fire cooker and with each second that passes the stress and pressure increases exponentially. No one wants to experience the day after a bad release.
The day after a release is always tense, everyone’s on standby waiting for any signs of trouble. Although I’m not making justice to real soldiers, it almost feels like being in the trenches waiting for the battle to begin. It can be nerve racking.
You’re hoping for a completely quiet day, but you’re prepared for the worse.
And that was us on Monday this week. The good thing is that it was a completely quiet day!!! Not a word. Not a peep. Nothing. The release went absolutely perfect. Not one hitch. The server got hammered by the sheer number of downloads but it held up without a problem. A lot of people upgraded based on the sheer number of downloads, but not one support request was related to the upgrade!
I couldn’t have asked for anything more. So far every single release of LandlordMax has gone really well. It’s been great. Of course I could say we’ve been very lucky, but I have to admit there is a lot of effort that goes into each release to make them successful. And it pays off. It’s worth the time, and I strongly recommend every company put the necessary effort into successfully releasing software rather than just throwing it out there and hoping for the best. It’s worth it.
And please don’t misconstrue this last comment as me saying that you should only release software when it’s fully complete feature wise, that’s not at all what I’m saying. I’m a big fan of evolutionary software, meaning build your software iteratively. Don’t try to build it all at one time, rather build as many features as you can now and add more later in future versions. It’s just that whatever you do build now, make sure it works to perfection.
Once I’ve written the follow-up article I promised on our sales metric here at LandlordMax, I’ll post an article about how to significantly improve the odds of successfully releasing a software. If you’re interested come back soon, or if you want to save yourself some effort, you can also subscribe to my RSS feed so that you don’t have to come back each day until I post the follow-up. As well you can subscribe to my email newsletter which will send each of the blog entries I publish to your email box directly.
Permalink to this article Discussions (1)
Why do Some Projects Continue to Push Unrealistic Software Development Schedules?

To quote one of my favorite software development books Rapid Development:
Some people seem to think that software projects should be scheduled optimistically because software development should be more an adventure than a dreary engineering exercise. These people say that schedule pressure adds excitement.
How much sense does that make? If you were going on a real adventure, say a trip to the south pole by dogsled, would you let someone talk you into planning for it to take only 30 days when your best estimate was that it would take 60? Would you carry only 30 days’ worth of food? Only 30 days’ worth of fuel? Would you plan for your sled dogs to be worn out at the end of 30 days rather than 60? Doing any of those things would be self-destructive, and underscoping and underplanning a software project is similarly self-destructive, albeit usually without any life-treatening consequences.
This analogy is all too accurate. You cannot wish for certain things to happen. Unfortunately reality is what it is.
One little tidbit that did catch my attention however, which I’m sure many people easily overlooked, is that if you really push a schedule beyonds reality is that you might not be able to re-adjust it later. For example if you push everyone to the extreme for 30 days they might not have any energy left at the end for another 30 days, or even more as is often the case. They will be “worn out”!
It’s virtually the same as asking someone to run a 100 meter sprint and then continually moving back the finish line as they’re just about done. It might work for a 200 meters, if you’re lucky maybe even 400 meters… But once you reach a certain threshold it will have very significant negative impacts. There’s a reason why people who run the 400 meters don’t sprint the 400 meters.
Ever try to sprint a mile? What about a marathon?

Permalink to this article Discussions (2)
Christmas Book Gift Ideas – Software Development
As Christmas is quickly approaching I thought it would be a great time to share with you a list of non-fiction books I really benefited from. Maybe it will give you some Christmas gift buying ideas, and if nothing else feel free to share it with your other half as a book buying gift list.
Each day will be a different category of books. Including:
- Software Development (language independent)
- Business
- Marketing and Sales
- Technology
- Investing
- Personal Success
- General (a catch all for remaining books that I learned from)
So feel free to bookmark and check often. If you subscribe to RSS feeds, this might be a good time so you don’t forget to check back this week.
So without further ado, here’s today’s list of software development books in no particular order (I’m sure I missed some but these are just the books I had in the bookcase behind my desk):















All the other software development books I have in bookcase behind my desk are either too language or technology specific (although books such as Concurrent Programming in Java are Java based, they are generic enough to be applied to any language).
And don’t forget to come back tomorrow to see my a list of business book Christmas ideas. You can also subscribe to my RSS feed so that you don’t forget. If you don’t know what an RSS feed is, don’t worry you can also subscribe to receive the articles by email here.
Permalink to this article Discussions (0)
What is Scope Creep?
To quote a simple definition I found online, scope creep is: “The tendency of a project to include more tasks or to implement more systems than originally specified, which often leads to higher than planned project costs and an extension of the initial implementation date.”
In other words it basically means a feature that was initially thought to be simple that’s exploding in scale. For us unfortunately this has already happened a few times with the next major release of LandlordMax. We wanted to offer Quickbooks support but that’s been postponed because of the scale. We also wanted to offer check printing but that’s been pushed to a future version as well. The latest feature which is experiencing some serious scope creep is full email support within LandlordMax. The good news is that we’re going to push this one through because I think we’ve finally limited it’s scope creep (and it’s much smaller, speaking very relatively).
That being said, I thought it would be an interesting read to go through our experience of what email support entailed, and just how quickly it exploded in scale.
The initial requirements were extremely simple. There were only two:
- Provide the ability to send emails within LandlordMax directly through a mail server and through Outlook.
- Provide the ability to import and export information (contacts) between LandlordMax and Outlook.
Both of these features have been highly requested for some time, and we thought it was time to add them in. Sounds simple. Send off an email, and import/export information. Nothing to it. Ah, if life were only that simple. Once we started to drill into the details of how to do this, it was no where near as simple as it first looks.
Before we go on, let me quickly ask you to make an estimate as to how long it would take to implement these two requirements? Take a second, or a minute, or whatever you think is reasonable, and do a quick cursory estimate. Write it down. We’ll compare your original estimate with another estimate at the end of this article and see what the difference is. My guess is you will be shocked.
Getting back, today I’ll only cover the second requirement because it’s the smaller one of the two. If I were to cover the first requirement (sending emails) it would be much longer. However to help you in reviewing and coming to a better final estimate I will finish off the article with questions on issues to be considered for the first requirement (sending emails within LandlordMax).
Let’s start with the second requirement, “Provide the ability to import/export information between LandlordMax and Outlook”. That should be simple. Just connect and share information. Ok, the first question is how do you connect? Do we build a connector? Do we buy a connector? What versions of Outlook do we support? Simple questions often have larger repercussions.
We initially started by looking at what was involved in building our own connector but quickly dropped this idea because it was not cost effective. Firstly we’d need to figure out how Outlook works, secondly we’d have to test each version of Outlook we’d want to support, and thirdly we’d have to continue supporting future version of Outlook. This is not where we add value for our customers. Therefore we decided to purchase a third party connector that will do this for us. Now comes the task of looking for a vendor that can do this in a nice, clean, simple way, and that doesn’t cost a fortune. All the while giving us a financially feasible way of redistributing the connector embedded within LandlordMax. We eventually found one that works with Outlook 2000, 2002, 2003, XP, and 2007. Great! One thing done.
Now that we can connect to Outlook, how do import/export information back and forth? What will the screen look like? What information will be exchanged. How do we know which contact we import are tenants, vendors, landlords, etc.? How do you import more than one at a time? What about contacts that don’t fit into these categories? What about synchronizing the data (if a change occurs in one will it be picked up in the other)? There’s a lot of options and choices here. And above all else, how do we do this in a very intuitive and user friendly way. If we didn’t have this last requirement it would be a lot easier. But that’s our main differentiator. We simplify the lives of our customers. We spend the time figuring out how to do it easily so that they don’t have to fight with the software, that’s why we’re the “EASIEST Property Management Software”.
Therefore, to answer the questions:
How do import/export information back and forth?
With the connector we decided to purchase this is just programming code.
What will the screen look like?
We’re still struggling with this one. We’ve got a good first pass implemented but we’re ironing out all the usability issues. Always trying to make it simpler. By the way, although I might be skimming this answer, it’s a very large one to which a lot of time has already been spent!
What information will be exchanged?
We’ll try to import and export as much information as possible. What this means is that we have to figure out all the mappings between the data in the two different products.
How do we know which imported contacts are tenants, vendors, landlords, etc.? How do you import more than one contact at a time?
This becomes a big part of how the import/export screen components will be drawn on the screen. Will there be drop down menu’s to select a type of contact? Will it be … ? The list goes on. We’re still determining the best solution. As an aside, if you only allow the user to import one contact at a time, this issue goes away, but that’s not a viable solution. Many people have lots of contacts, in the hundreds. It’s really not a viable solution to ask them to import their contacts one at a time.
What about contacts that don’t fit into these neat categories?
This one might seem simple, but it resulted in a huge scope creep! Maybe you have real estate agents you want to store within LandlordMax. Maybe you have bankers, etc. So what we ended up with was a completely new Workarea (section) called Contacts. Simple, just a new area to enter in data. Not so fast!!!
With each new area comes filters. You have to be able to filter the data. Ok, that’s not too bad. But wait, what about reporting. You need to be able to generate reports on the new Contacts. So we added Contacts to the Reporting workarea and create several new reports. Is that it? Nope. Still more. On top of creating the new tables, you need to be able to support upgrading existing databases to handle Contacts. Ok, we’re done now right? You would think so but not yet. The list just goes on. Basically this ended up being a costly extra that we hadn’t planned. But the benefit is that we also end up with a new feature that other people have been requesting, a way to store other contacts.
What about synchronizing the data (if a change occurs in one application’s contact will it be picked up in the other)?
For the current version we’re not offering synchronization of the contacts. That just too massive a feature to implement. Although it might seem simple at first glance, synchronizing data is complex. It’s so complex that it extended the release beyond when I’m willing to accept. So for now a synchronization feature has been postpone.
To quickly give you an idea of the effort involved in synchronizing data between the two applications, here are some common issues that must be correctly dealt with. Which data has already been synchronized? For example I have a contact in Outlook called “Stephane Grenier” and I add him to LandlordMax as a landlord. Then on another attempt I go to synchronize again. Is this the same contact? How do I know? What is the identifying characteristic (the unique key)? Is it the name? If so, what happens if I change the name to “Steph Grenier” because of a typo? Do I create a new entry? What about the existing “Stephane Grenier”? Do I delete that one since it no longer exists? As you can see it quickly escalates in complexity to deal with all the possible scenario’s.
What generally happens with synchronization algorithms is that you have a basic set of rules for which the user corrects the data afterwards. Merging data has always been tough. There are many tools just to merge two text files (it doesn’t get any simpler than that). Text files! Not contact data across different applications in different sections of the applications. It’s not a simple task. Although nice, we’ve decided that it for now our customers can just re-import data if they want to. It’s more valuable to our customer to get the release out sooner than holding it back for this feature. And holding it back could be quite long…
So far we’ve just talked about scope creep for the second requirement, importing and exporting contacts from Outlook. This is the smaller of the two requirements by far. I’ll leave it as an exercise to the reader to think about the sending of emails as a requirement. Here are just a few of the issues we had to resolve:
- How do you select which method to use to to send emails (directly through the mailserver or through Outlook) without annoying the user with popup choices each time?
- How do you pick which email address to send it from?
- How do you support multiple send email addresses?
- Do you record sent emails? If so where? How do you access them later?
- How do you create the body for the emails? What about spellchecking? What about advanced editing (bold, italics, etc.) How much effort will it take?
- How do you send an email to multiple contacts at once? What if they’re different types of contacts? A tenant and a landlord?
- How do you send a generated report as an attachment?
- How do you send an email to all your tenants? What if you want to exclude some tenants?
- How do you filter the contacts (say tenants) you send the emails to (for example Current tenants only)? How do you make this generic enough?
- How do you send an email to all your tenants with only some variables different (for example send each of your tenants reminders that their rent is due in three days, with their specific amounts displayed in the email) – By the way this is one of the larger email features we’ve postponed for now.
- How do you send emails to people not in your contacts list? Can you create new contacts directly from the send email window?
- Can you receive emails? (this won’t be supported within LandlordMax for now either).
- How do you integrate email on every data screen to easily offer the ability to send emails to the current person you’re looking at (for example tenant, vendor, etc.)
- How do you integrate sending emails in the list view to the selected rows?
- How do you make all this very user friendly and very intuitive (above all else!!!)
And this is only a quick list that I came up with right now on the spot. The list goes on. I know we faced several other issues. And I’m still expecting a few more new ones to make their appearance.
At this point I’ll ask you to re-estimate the total effort needed to implement the initial two requirements. Rather than just say it’s a lot more, I recommend you go through the exercise of actually thinking about it for at least a few moments. What did you come up with? How many times larger was your final estimate? Notice I asked “how many times”, not “what percentage”. I suspect that for many of you it’s many times larger.
What’s happened is that a simple requirement has exploded in terms of scale and effort required because we hadn’t fully analyzed it beforehand. I doubt it would have been possible without getting our hands dirty trying to implement it. Without hindsight it’s almost impossible. Having gone through the experience it’s easy for me to direct you in the right direction in terms of effort required. But without this hindsight it would be almost impossible. How much effort do you think is required to support Quickbooks? What about check printing?
Along the way we’ve had to make hard choices on what features we’re going to implement and what features will have to be postponed. This is what software development and project management is all about. Making choices. Right or wrong decisions have to be made in terms of what gives you and your customers the best value for the money. Scope creep happens. Features that weren’t planned need to be implemented. A good project manager will be able to, at least more than often than not, make the right decisions as to what features are in fact necessary and which are truly scope creep. This is the fun of project management.
Permalink to this article Discussions (5)
Developer Debt
Many software developers are aware of this concept but few actually know it by name. It probably doesn’t help that there a variety of names it too. It’s called Developer Debt, Technical Debt, and so on. At the end of the day, Developer Debt means taking the quick and dirty way today knowing that tomorrow we’ll have to pay more to fix the issue because it will have evolved into a bigger problem, hence the idea of debt with interest.
Virtually all software development shops have to deal with the balance of developer debt on an ongoing basis. The problem is that it’s very easy, much like financial debt, to acquire it now and ignore the fact that we’ll have to pay for it later, with interest. It’s much easier to implement a quick fix today and ignore the longer term costs because we’re dealing with today, with this quarter, with this release, with now. Tomorrow may never come, and even if it does, it’s tomorrow and not today. Tomorrow we’ll have more resources. Maybe, but tomorrow the problem will also be much bigger because it will be embedded even more, other hacks will be included to work around the original hack we’ve just introduced, the code base will be larger (more places in the code will be affected), the original developers may be gone, the list goes on…
What will happen is that eventually the software will become such a mess that adding new features will be next to impossible. They will cost a fortune. They’ll be buggy. No one will really know how to do it. Every new fix will just be another hack (I’ve seen this on more projects than I wish to acknowledge). Things can quickly get out of hand. Just like credit cards, it’s very easy to keep spending to keep up with your neighbors and forget that one day you will have to pay the balance due.
In addition to this, as a little side note before continuing, there’s a concept called the Broken Window Syndrome that will come and take hold of your project. In essence (without explaining the original study which you can find here), what this means is that if you let a few small things fall apart, pretty soon other bigger things will also start to degrade. And before you realize it you can end up with a mess of a code base where you can no longer remain competitive.
Going back to developer debt, what often happens is that companies get hit with “major architectural releases”, “rewrites”, etc. Basically large parts of the code base need to be rewritten for the software to continue evolving. It comes to a point where nothing can done in any reasonable time or method. For companies that don’t learn, this process gets repeated very frequently as you can see from the following graph. (If any of you know who originated this graph please let me know as I can’t recall where I was introduced to it.)
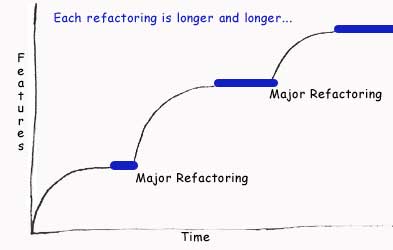
As you can see from the graph, what’s happening is that you initially get a lot of activity. Software development is moving along at a very rapid pace. People are happy. Things are getting done. Features are being added. Things are going smooth.
Then slowly but surely features start taking longer to be added. More bugs are introduced. People start to add quick fixes, quick temporary solutions, hacks. “We don’t have time to fix it properly so we’ll just do this this one and only time and fix for the next version.” So at first the slowing of the graph is almost imperceptible. Then over time you start to hear the developers complain how hard it is to do anything. At first it’s a few faint whispers from the development team than it becomes the main water cooler talk for the whole company. Things start to take a very long time to get done. New people can’t get up to speed in any decent amount of time. Everyone needs to learn how “things are done here”.
At this point you start to realize that something is wrong. For many this is the time where they realize something drastic needs to be done. The code can’t just quickly be fixed anymore. Maybe the software needs to be “updated”. Maybe the architecture needs to be refactored. Maybe a rewrite (I strongly suggest you think hard before deciding to do a full rewrite). Whatever the case something needs to be done. If you’re one of the unlucky few, then this will continue to be delayed indefinitely until the company expires. The hacks will become more obvious leading to insanity for lack of better word. It will eventually collapse the company.
But if you’re one of the luckier few, the company will decide to invest in upgrading the quality of the code. This will take time. There is no magic bullet. At this point it’s where you get hit with developer debt. All those items you’ve been pushing off are now coming back to bite you, and bit you hard they will. What was once a simple little hack has now grown into a full blown framework that’s completely inadequate. Simple fixes have now escalated into large structural changes. Not only is the capital due, but it’s due with interest!
Of course this never happens at a good time. Is there ever a good time? Nonetheless this generally happens after a company has begun to pick up steam. After all it won’t happen in the initial stages, there’s nothing to hack at that point. It generally happens when a new company is starting to really get going, when they need to be running at full speed. Of course once they’ve got the ball rolling, it’s hard to take a step back to catch up. They need to keep going at full throttle to keep the ball rolling. Momentum at this stage is important.
As an analogy, imagine that it’s financial debt. You’re starting a business. You put money in. At first you don’t have any real debt but within a short time you start to use your credit card to pay for smaller items. Within a year you’ve got a balance but you’re business is growing so you decide to push off the debt repayment. After all you need all the capital you can to grow your business as fast as possible. Then another year or two go by and you’ve added more debt. Maybe you’ve also added a line of credit to your corporation. No matter what the medium is, suddenly you find yourself with more and more debt. Sure you’re making more money but the monthly payments on your debt are now starting to hold you back. You’re using all your cash flow to just make the monthly payments. What do you do? Get more debt? Possibly. But at some point you need to settle this debt otherwise its weight will suffocate you. This is where you start to imagine what it would be like without debt. Just imagine if we didn’t have to use 50% of our revenues to pay our debt. Our cash flow would be so much higher. We could invest in the future. We could really grow!
And unfortunately this is where a lot of companies stall or go bankrupt. Something has to be done to resolve the debt. It cannot keep going. You no longer have any free cash flow to grow. You need to bite the bullet and resolve your fiduciary issues. Yes you can get funding and use the money to resolve all your issues, but if you don’t learn your lesson you will be doomed to repeat it.
Are there alternatives? Is every software company doomed to repeat this cycle? Absolutely not! I’m a very strong proponent of the Agile development process, also known as RAPID development. It’s not a magic bullet, there is no magic bullet. Magic bullets don’t exist, hence why they’re called “magic” bullets. What Agile development does is allow you to smooth out the curves from the above graph. Rather than large growth periods followed by really slow growth periods, it smoothens it out. Rather than paying interest in large amounts at inconvenient times, it stops you from accumulating interest.
Unlike what most people think, Agile development is not easy. It requires a lot of dedication and commitment. It requires continually adherence to the concept that no hacks should be left within the system. No kludges. Everything should be continually “upgraded”. No ugly hacks should be introduced. No quick fixes should be added. Architectural changes shouldn’t be postponed. If something needs to be fixed, do it now. Don’t delay it. This is why I actually find it’s “harder” but well worth it.
You also have to remember that along with software development needs there are business needs. It’s easy for a developer to say we have to hold back a bit “to do it right”. But the business still has it’s financial needs. People need to get paid. The rent needs to be covered. Things have to move forward.
It’s the fine balance between over extending yourself versus paying everything cash. Most business like to deal with leverage (debt). Most people behave the same. Most people use credit cards to finance their current lifestyles, hence the impending credit crunch we’re now facing. Nevertheless, the Agile proponents favor cash deals. Everything is paid in cash now. You don’t acquire any debt, you pay for what you can now. Much like personal finances. Don’t buy what you can’t afford in cash today.
As simple as this model is, it is limited. I do believe that debt can be good as long as it’s properly managed. The problem is most people can’t properly manage debt. Especially when decisions on how much debt to acquire are made when you’re trying to go a million miles an hour to get your next release done. With the Agile development process, at least you slow this down significantly to a manageable level. And you limit the amount of debt you will acquire.
Although short term it may seem limiting, realize that within a few years you’ll be about even with the company that pushes out hacks in terms of feature count. Debt and it’s interest will start to drag them down, slowing them to snails pace. And within five or so years you will be further ahead and moving faster than them. You’re growth curve will never be straight, that’s too idealistic, but it will be significantly smoother and inclined. It will not taper off over time, you will continue your same momentum and overtake your competition within a short time as their curve starts to deteriorate. And once you’ve overtaken your competition they will never be able to catch up to you because you won’t have the ball and chain of debt slowing you down.
Permalink to this article Discussions (4)
What Does it Take for a Software Framework to Become Mainstream?
Firstly, and most obviously, for any software framework to become mainstream it has to be good. Ignoring what good means, what else does it take? Good documentation! Right now in the Ajax world there are many frameworks coming out trying to be the “one” main framework. The problem is that although several are really good, there’s virtually no documentation for any of them. Talk about a great opportunity to take over a market.
For example, today I was looking at the Dojo toolkit. It looks very promising. It can do some amazing stuff. But there’s virtually no documentation. The only documentation that’s available is for the older version (which is significantly different), and even that’s very sparse. The only documentation is the code examples. Problem is that Javascript is not a strongly typed programming language, and nor is there really a great IDE solution that lets you work with it. So you end up having to go back to the “old school” way of learning code. Opening files one at a time, trying to figure out where a variable was defined, what type it is, what it really does. This is extremely tedious, frustrating, and especially time consuming. But worse than that, it makes for a very high learning curve since some of these frameworks are pretty large and complex.
And Dojo isn’t the only guilty framework here. Open-jACOB is another one that looked really promising (especially Draw2D) but it was next to impossible to figure out. The demos are amazing. Good luck figuring them out though. The list goes on. Even Ext-JS which currently has the best documentation among all of them is mediocre documentation at best. What saves them is their forum. But having the forum be a main source of documentation is not a good solution. A lot of time is lost trying to find the relevant threads, and then finding the right answer.



If you look at the Java world, everyone is familiar with Struts. Back in the day Struts was the main J2EE framework to develop by. It was decent framework for its era. Whether or not it was the best is debatable, but it was popular because figure out how to use it. It had good documentation. They did a good job of documenting it. It can always be better but they at least brought it to a point where you weren’t always frustrated trying to figure out how to do the next thing. The latest Spring and MyFaces frameworks are also experiencing success for similar reasons.
It takes more than just being a good framework to become mainstream. Above being easy to learn and use, it also has to be well documented. I remember back in the day looking at alternative frameworks to Struts (when it was the new kid on the block) and getting frustrated. Although today I no longer use Struts, it did have its moment in the sun. And I personally believe one of the main reasons it did became so famous was because of its documentation. If you can’t figure it out odds are you won’t use it.
So my quick tip of the day: if you’re one of the several new Ajax frameworks vying to dominate the market look at improving your documentation sooner than later. Many of you have amazing features but if we can’t figure out how to implement them, then we just won’t. I know that if one of the frameworks I played with today was easy to learn and properly documented, odds are very high I would have gone with it, even if it wasn’t complete! There’s a great opportunity here, nows your chance to seize it.
Permalink to this article Discussions (2)
| « PREVIOUS PAGE | NEXT PAGE » |




